

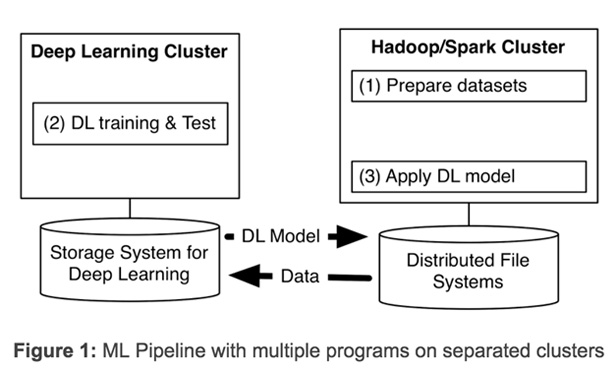
Yahoo has announced TensorFlowOnSpark, its latest open source framework for distributed deep learning on big-data clusters. Deep learning (DL) has evolved significantly in recent years. At Yahoo, we’ve found that in order to gain insight from massive amounts of data, we need to deploy distributed deep learning. Existing DL frameworks often require us to set up separate clusters for deep learning, forcing us to create multiple programs for a machine learning pipeline (see Figure 1 below). Having separate clusters requires us to transfer large datasets between them, introducing unwanted system complexity and end-to-end learning latency.
Last year Yahoo addressed scaleout issues by developing and publishing CaffeOnSpark, our open source framework that allows distributed deep learning and big-data processing on identical Spark and Hadoop clusters. We use CaffeOnSpark at Yahoo to improve our NSFW image detection, to automatically identify eSports game highlights from live-streamed videos, and more. With the community’s valuable feedback and contributions, CaffeOnSpark has been upgraded with LSTM support, a new data layer, training and test interleaving, a Python API, and deployment on docker containers. This has been great for our Caffe users, but what about those who use the deep learning framework TensorFlow? We’re taking a page from our own playbook and doing for TensorFlow for what we did for Caffe.
After TensorFlow’s initial publication, Google released an enhanced TensorFlow with distributed deep learning capabilities in April 2016. In October 2016, TensorFlow introduced HDFS support. Outside of the Google cloud, however, users still needed a dedicated cluster for TensorFlow applications. TensorFlow programs could not be deployed on existing big-data clusters, thus increasing the cost and latency for those who wanted to take advantage of this technology at scale.
To address this limitation, several community projects wired TensorFlow onto Spark clusters. SparkNet added the ability to launch TensorFlow networks in Spark executors. DataBricks proposed TensorFrame to manipulate Apache Spark’s DataFrames with TensorFlow programs. While these approaches are a step in the right direction, after examining their code, we learned we would be unable to get the TensorFlow processes to communicate with each other directly, we would not be able to implement asynchronous distributed learning, and we would have to expend significant effort to migrate existing TensorFlow programs.
Yahoo’s new framework, TensorFlowOnSpark (TFoS), enables distributed TensorFlow execution on Spark and Hadoop clusters. As illustrated in Figure 2 above, TensorFlowOnSpark is designed to work along with SparkSQL, MLlib, and other Spark libraries in a single pipeline or program (e.g. Python notebook). TensorFlowOnSpark supports all types of TensorFlow programs, enabling both asynchronous and synchronous training and inferencing. It supports model parallelism and data parallelism, as well as TensorFlow tools such as TensorBoard on Spark clusters.
Any TensorFlow program can be easily modified to work with TensorFlowOnSpark. Typically, changing fewer than 10 lines of Python code are needed. Many developers at Yahoo who use TensorFlow have easily migrated TensorFlow programs for execution with TensorFlowOnSpark. TensorFlowOnSpark supports direct tensor communication among TensorFlow processes (workers and parameter servers). Process-to-process direct communication enables TensorFlowOnSpark programs to scale easily by adding machines. As illustrated in Figure 3, TensorFlowOnSpark doesn’t involve Spark drivers in tensor communication, and thus achieves similar scalability as stand-alone TensorFlow clusters.
TensorFlowOnSpark provides two different modes to ingest data for training and inference:
- TensorFlow QueueRunners: TensorFlowOnSpark leverages TensorFlow’s file readers and QueueRunners to read data directly from HDFS files. Spark is not involved in accessing data.
- Spark Feeding: Spark RDD data is fed to each Spark executor, which subsequently feeds the data into the TensorFlow graph via feed_dict.
RDMA for Distributed TensorFlow
In Yahoo’s Hadoop clusters, GPU nodes are connected by both Ethernet and Infiniband. Infiniband provides faster connectivity and supports direct access to other servers’ memories over RDMA. Current TensorFlow releases, however, only support distributed learning using gRPC over Ethernet. To speed up distributed learning, we have enhanced the TensorFlow C++ layer to enable RDMA over Infiniband.
In conjunction with our TFoS release, we are introducing a new protocol for TensorFlow servers in addition to the default “grpc” protocol. Any distributed TensorFlow program can leverage our enhancement via specifying protocol=“grpc_rdma” in tf.train.ServerDef() or tf.train.Server().
With this new protocol, a RDMA rendezvous manager is created to ensure tensors are written directly into the memory of remote servers. We minimize the tensor buffer creation: Tensor buffers are allocated once at the beginning, and then reused across all training steps of a TensorFlow job. From our early experimentation with large models like the VGG-19 network, our RDMA implementation has demonstrated a significant speedup on training time compared with the existing gRPC implementation.