

Oath, a Verizon subsidiary, announced the open sourcing of Vespa, Yahoo’s big data processing and serving engine, available as open source on GitHub. Ever since Yahoo open sourced Hadoop in 2006, the brand – now Oath – has been committed to opening up its big data infrastructure to the larger developer community.
Building applications increasingly means dealing with huge amounts of data. While developers can use the Hadoop stack to store and batch process big data, and Storm to stream-process data, these technologies do not help with serving results to end users. Serving is challenging at large scale, especially when it is necessary to make computations quickly over data while a user is waiting, as with applications that feature search, recommendation, and personalization.
By releasing Vespa, we are making it easy for anyone to build applications that can compute responses to user requests, over large datasets, at real time and at internet scale – capabilities that up until now, have been within reach of only a few large companies.
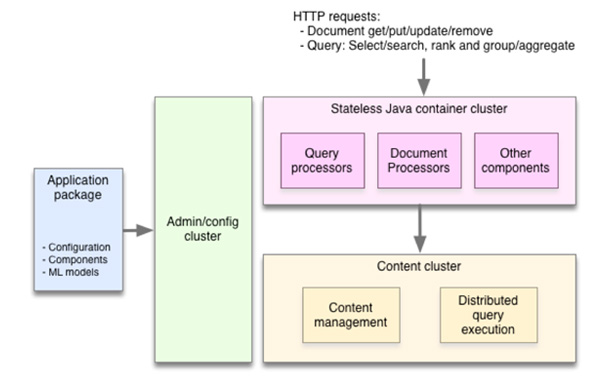
Serving often involves more than looking up items by ID or computing a few numbers from a model. Many applications need to compute over large datasets at serving time. Two well-known examples are search and recommendation. To deliver a search result or a list of recommended articles to a user, you need to find all the items matching the query, determine how good each item is for the particular request using a relevance/recommendation model, organize the matches to remove duplicates, add navigation aids, and then return a response to the user. As these computations depend on features of the request, such as the user’s query or interests, it won’t do to compute the result upfront. It must be done at serving time, and since a user is waiting, it has to be done fast. Combining speedy completion of the aforementioned operations with the ability to perform them over large amounts of data requires a lot of infrastructure – distributed algorithms, data distribution and management, efficient data structures and memory management, and more. This is what Vespa provides in a neatly-packaged and easy to use engine.
With over 1 billion users, we currently use Vespa across many different Oath brands – including Yahoo.com, Yahoo News, Yahoo Sports, Yahoo Finance, Yahoo Gemini, Flickr, and others – to process and serve billions of daily requests over billions of documents while responding to search queries, making recommendations, and providing personalized content and advertisements, to name just a few use cases. In fact, Vespa processes and serves content and ads almost 90,000 times every second with latencies in the tens of milliseconds. On Flickr alone, Vespa performs keyword and image searches on the scale of a few hundred queries per second on tens of billions of images.
Additionally, Vespa makes direct contributions to our company’s revenue stream by serving over 3 billion native ad requests per day via Yahoo Gemini, at a peak of 140k requests per second (per Oath internal data).
With Vespa, our teams build applications that:
- Select content items using SQL-like queries and text search
- Organize all matches to generate data-driven pages
- Rank matches by handwritten or machine-learned relevance models
- Serve results with response times in the lows milliseconds
- Write data in real-time, thousands of times per second per node
- Grow, shrink, and re-configure clusters while serving and writing data
To achieve both speed and scale, Vespa distributes data and computation over many machines without any single master as a bottleneck. Where conventional applications work by pulling data into a stateless tier for processing, Vespa instead pushes computations to the data. This involves managing clusters of nodes with background redistribution of data in case of machine failures or the addition of new capacity, implementing distributed low latency query and processing algorithms, handling distributed data consistency, and a lot more.